CAP THEOREM
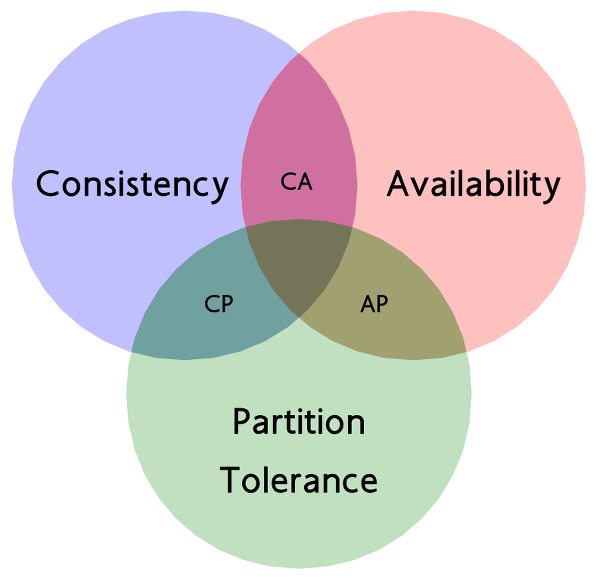
What’s C, A and P?
Consistency is the easiest one. It roughly means that the clients get the same view of data. By saying that a system is consistent we often mean strong consistency, but it also can come in different flavors.
Availability is a property saying that every request to a non-failing node will return a (meaningful) response. The response may not contain all data (so the harvest will not be 100%), but it should be useful for the client.
Partition tolerance means that the system will continue working even if any number of messages sent between nodes is lost. This can be
e.g. a network failure between two data centers, where nodes in each data center form a partition. Also note that a failure of any number of nodes forms a partition (it is not possible to distinguish between a network failure and a node failing and stopping to respond to messages).
The basic statement of the CAP theorem is that, given the three properties of Consistency, Availability, and Partition tolerance, you can only get two. Obviously this depends very much on how you define these three properties, and differing opinions have led to several debates on what the real consequences of the CAP theorem are.
Consistency is pretty much as we’ve defined it so far. Availability has a particular meaning in the context of CAP, it means that if you can talk to a node in the cluster, it can read and write data. Partition tolerance means that the cluster can survive communication breakages in the cluster that separate the cluster into multiple partitions unable to communicate with each other.
With two breaks in the communication lines, the network partitions into two groups.
A single-server system is the obvious example of a CA system. A system that has Consistency and Availability but not Partition tolerance. A single machine can’t partition, so it does not have to worry about partition tolerance. There’s only one node, so if it’s up, it’s available. Being up and keeping consistency is reasonable. This is the world that most relational database systems live in. It is theoretically possible to have a CA cluster. However, this would mean that if a partition ever occurs in the cluster, all the nodes in the cluster would go down so that no client can talk to a node.
By the usual definition of available, this would mean a lack of availability, but this is where CAP’s special usage of “availability” gets confusing. CAP defines “availability” to mean “every request received by a non failing node in the system must result in a response”. So a failed, unresponsive node doesn’t infer a lack of CAP availability.
Why is it important?
- The future of databases is distributed (Big Data Trend, etc.)
- CAP theorem describes the trade-offs involved in distributed systems
- A proper understanding of CAP theorem is essential to making decisions about the future of distributed database design
- Misunderstanding can lead to erroneous or inappropriate design choices
Dealing with CAP
You’ve got a few choices when addressing the issues thrown up by CAP. The obvious ones are:
1. Drop Partition Tolerance
If you want to run without partitions you have to stop them happening. One way to do this is to put everything (related to that transaction) on one machine, or in one atomically-failing unit like a rack. It’s not 100% guaranteed because you can still have partial failures, but you’re less likely to get partition-like side-effects. There are, of course, significant scaling limits to this.
2. Drop Availability
This is the flip side of the drop-partition-tolerance coin. On encountering a partition event, affected services simply wait until data is consistent and therefore remain unavailable during that time. Controlling this could get fairly complex over many nodes, with re-available nodes needing logic to handle coming back online gracefully.

Selecting Two Requirements at a Time
CA
|
All relational DBs are CA.
Single site clusters to ensure that all nodes are always in contact, e.g., 2 PCs.
When a partition occurs, the system blocks.
|
CP
|
Some data may be inaccessible (availability sacrificed), but the rest is still consistent/accurate, e.g., shared database.
|
AP
|
The system is still available under partitioning, but some returned data may be inaccurate, e.g., DNS, caches, Master/Slave replication.
Needs a conflict resolution strategy.
|
The decision between Consistency and Availability is a software trade off. You can choose what to do in the face of a network partition - the control is in your hands. Network outages, both temporary and permanent, are a fact of life and occur whether you want them to or not - this exists outside of your software.
Building distributed systems provide many advantages, but also adds complexity. Understanding the trade-offs available to you in the face of network errors, and choosing the right path is vital to the success of your application. Failing to get this right from the beginning could doom your application to failure before your first deployment.


Comments
Post a Comment